DP-203 dumps have been updated. Contains 243 new exam questions, real material for you to pass the Data Engineering on Microsoft Azure exam.
The full name of the DP-203 exam is Data Engineering on Microsoft Azure. DP-203 dumps question targets from Data Engineering on Microsoft Azure core technologies including:
design and implement data storage; design and develop data processing; design and implement data security; monitor and optimize data storage and data processing.
leads4pass DP-203 Dumps Questions https://www.leads4pass.com/dp-203.html: Contains both PDF and VCE study modes, easy to study anytime, anywhere, helping you successfully pass the Data Engineering on Microsoft Azure exam on the first try.
Read the DP-203 Free Dumps Demo
QUESTION 1
What should you recommend to prevent users outside the Litware on-premises network from accessing the analytical data store?
A. a server-level virtual network rule
B. a database-level virtual network rule
C. a server-level firewall IP rule
D. a database-level firewall IP rule
Correct Answer: A
Scenario: Ensure that the analytical datastore is accessible only to the company\’s on-premises network and Azure services.
Virtual network rules are one firewall security feature that controls whether the database server for your single databases and elastic pool in Azure SQL Database or for your databases in SQL Data Warehouse accepts communications that are sent from particular subnets in virtual networks.
Server-level, not database-level: Each virtual network rule applies to your whole Azure SQL Database server, not just to one particular database on the server. In other words, the virtual network rule applies at the server level, not at the database level.
Reference: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-vnet-service-endpoint-rule-overview
QUESTION 2
You are designing a slowly changing dimension (SCD) for supplier data in an Azure Synapse Analytics dedicated SQL pool.
You plan to keep a record of changes to the available fields.
The supplier data contains the following columns.
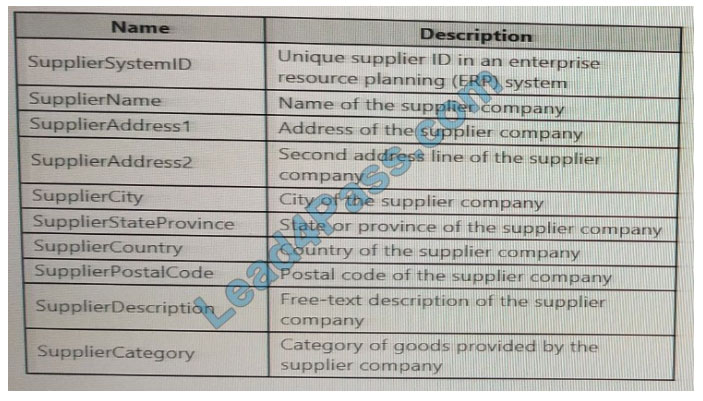
Which three additional columns should you add to the data to create a Type 2 SCD? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. surrogate primary key
B. foreign key
C. effective start date
D. effective end date
E. last modified date
F. business key
Correct Answer: CDF
QUESTION 3
HOTSPOT
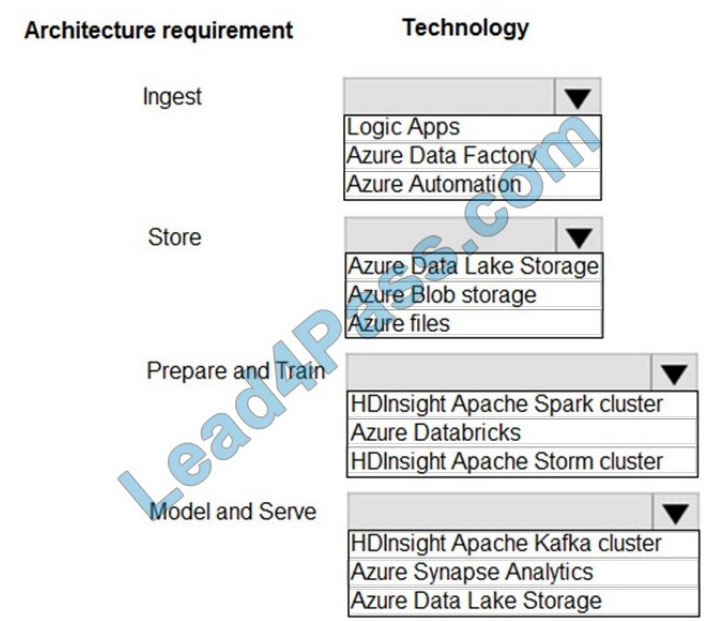
A company plans to use Platform-as-a-Service (PaaS) to create the new data pipeline process. The process must meet the following requirements:
Ingest:
1.
Access multiple data sources.
2.
Provide the ability to orchestrate workflow.
3.
Provide the capability to run SQL Server Integration Services packages.
Store:
1.
Optimize storage for big data workloads.
2.
Provide encryption of data at rest.
3.
Operate with no size limits.
Prepare and Train:
1.
Provide a fully-managed and interactive workspace for exploration and visualization.
2.
Provide the ability to program in R, SQL, Python, Scala, and Java.
3.
Provide seamless user authentication with Azure Active Directory.
Model and Serve:
1.
Implement native columnar storage.
2.
Support for the SQL language
3.
Provide support for structured streaming.
You need to build the data integration pipeline.
Which technologies should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:
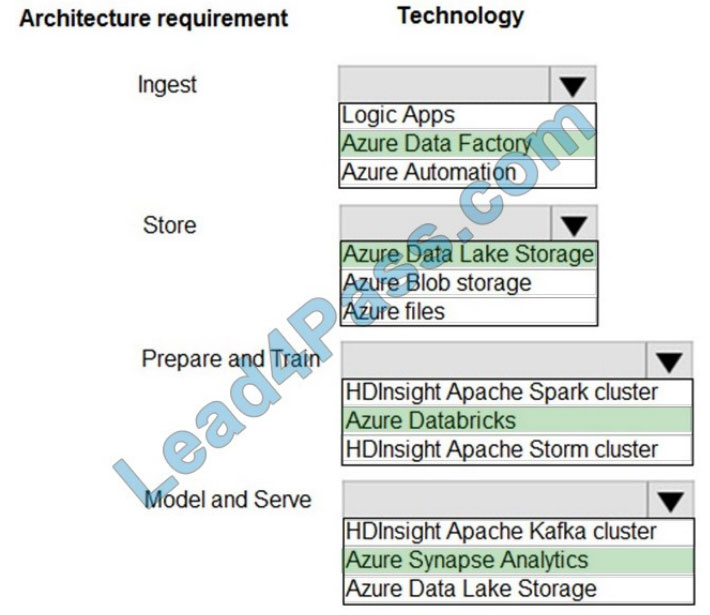
Ingest: Azure Data Factory
Azure Data Factory pipelines can execute SSIS packages.
In Azure, the following services and tools will meet the core requirements for pipeline orchestration, control flow, and data movement: Azure Data Factory, Oozie on HDInsight, and SQL Server Integration Services (SSIS).
Store: Data Lake Storage
Data Lake Storage Gen1 provides unlimited storage.
Note: Data at rest includes information that resides in persistent storage on physical media, in any digital format.
Microsoft Azure offers a variety of data storage solutions to meet different needs, including file, disk, blob, and table storage.
Microsoft also provides encryption to protect Azure SQL Database, Azure Cosmos DB, and Azure Data Lake.
Prepare and Train: Azure Databricks
Azure Databricks provides enterprise-grade Azure security, including Azure Active Directory integration.
With Azure Databricks, you can set up your Apache Spark environment in minutes, autoscale and collaborate on shared projects in an interactive workspace. Azure Databricks supports Python, Scala, R, Java, and SQL, as well as data science frameworks and libraries including TensorFlow, PyTorch, and scikit-learn.
Model and Serve: Azure Synapse Analytics
Azure Synapse Analytics/ SQL Data Warehouse stores data into relational tables with columnar storage.
Azure SQL Data Warehouse connector now offers efficient and scalable structured streaming write support for SQL
Data Warehouse. Access SQL Data Warehouse from Azure Databricks using the SQL Data Warehouse connector.
Note: Note: As of November 2019, Azure SQL Data Warehouse is now Azure Synapse Analytics.
Reference:
https://docs.microsoft.com/en-us/azure/azure-databricks/what-is-azure-databricks
QUESTION 4
You need to schedule an Azure Data Factory pipeline to execute when a new file arrives in an Azure Data Lake Storage Gen2 container. Which type of trigger should you use?
A. on-demand
B. tumbling window
C. schedule
D. event
Correct Answer: B
Event-driven architecture (EDA) is a common data integration pattern that involves production, detection, consumption, and reaction to events. Data integration scenarios often require Data Factory customers to trigger pipelines based on events happening in the storage account, such as the arrival or deletion of a file in the Azure Blob Storage account.
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/how-to-create-event-trigger
QUESTION 5
HOTSPOT
You need to design an analytical storage solution for transactional data. The solution must meet the sales
transaction dataset requirements.
What should you include in the solution? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
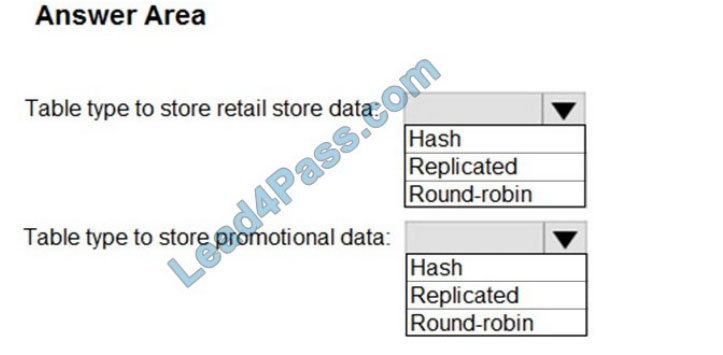
Correct Answer:
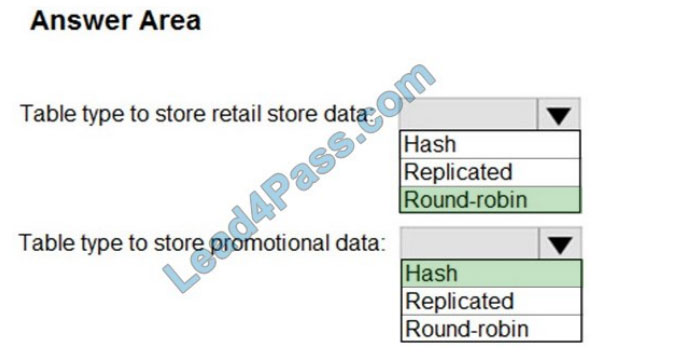
Box 1: Round-robin
Round-robin tables are useful for improving loading speed.
Scenario: Partition data that contains sales transaction records. Partitions must be designed to provide efficient loads by month.
Box 2: Hash
Hash-distributed tables improve query performance on large fact tables.
Scenario:
1.
You plan to create a promotional table that will contain a promotion ID. The promotion ID will be associated with a specific
product. The product will be identified by a product ID. The table will be approximately 5 GB.
2.
Ensure that queries joining and filtering sales transaction records based on product ID are completed as quickly as possible.
QUESTION 6
HOTSPOT
You are designing an Azure Stream Analytics solution that receives instant messaging data from an Azure event hub.
You need to ensure that the output from the Stream Analytics job counts the number of messages per time zone every 15 seconds.
How should you complete the Stream Analytics query? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer:
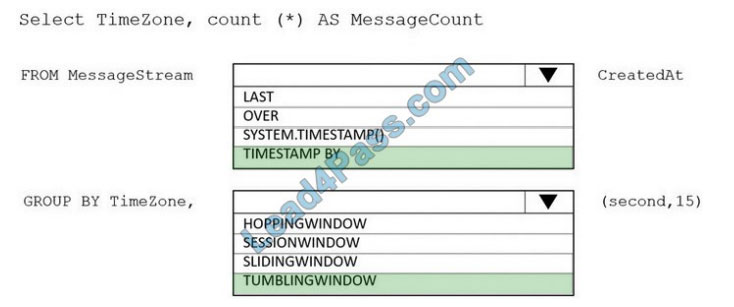
Box 1: timestamp by
Box 2: TUMBLINGWINDOW
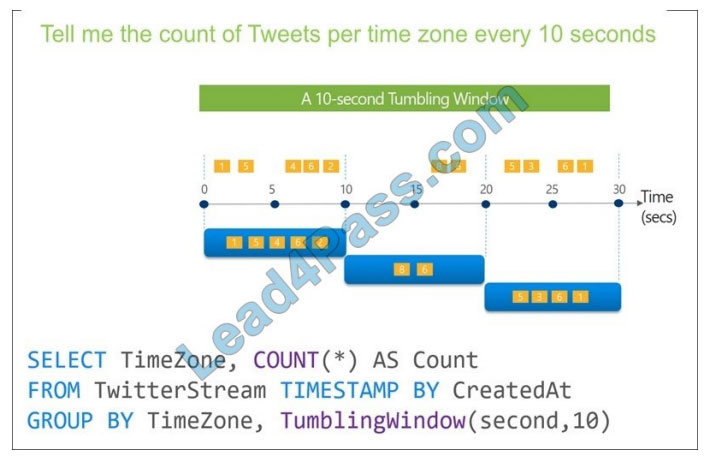
Tumbling window functions are used to segment a data stream into distinct time segments and perform a function against them, such as the example below. The key differentiators of a Tumbling window are that they repeat, do not overlap, and an event cannot belong to more than one tumbling window.
QUESTION 7
You need to design a data retention solution for the Twitter teed data records. The solution must meet the customer sentiment analytics requirements. Which Azure Storage functionality should you include in the solution?
A. time-based retention
B. change feed
C. soft delete
D. Lifecycle management
Correct Answer: D
Scenario: Purge Twitter feed data records that are older than two years.
Data sets have unique lifecycles. Early in the lifecycle, people access some data often. But the need for access often drops drastically as the data ages. Some data remains idle in the cloud and is rarely accessed once stored. Some data sets expire days or months after creation, while other data sets are actively read and modified throughout their lifetimes.
Azure Storage lifecycle management offers a rule-based policy that you can use to transition blob data to the appropriate access tiers or to expire data at the end of the data lifecycle.
Reference:
https://docs.microsoft.com/en-us/azure/storage/blobs/lifecycle-management-overview
QUESTION 8
HOTSPOT
You are designing an application that will use an Azure Data Lake Storage Gen 2 account to store petabytes of license plate photos from toll booths. The account will use zone-redundant storage (ZRS).
You identify the following usage patterns:
1.
The data will be accessed several times a day during the first 30 days after the data is created.
2.
The data must meet an availability SU of 99.9%.
3.
After 90 days, the data will be accessed infrequently but must be available within 30 seconds.
4.
After 365 days, the data will be accessed infrequently but must be available within five minutes.
Hot Area:

Correct Answer:

QUESTION 9
You are designing a security model for an Azure Synapse Analytics dedicated SQL pool that will support multiple companies.
You need to ensure that users from each company can view only the data of their respective companies.
Which two objects should you include in the solution? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. a security policy
B. a custom role-based access control (RBAC) role
C. a function
D. a column encryption key
E. asymmetric keys
Correct Answer: AB
A: Row-Level Security (RLS) enables you to use group membership or execution context to control access to rows in a database table. Implement RLS by using the CREATE SECURITY POLICYTransact-SQL statement.
B: Azure Synapse provides a comprehensive and fine-grained access control system, that integrates:
Azure roles for resource management and access to data in storage, Synapse roles for managing live access to code and execution, SQL roles for data plane access to data in SQL pools.
Reference: https://docs.microsoft.com/en-us/sql/relational-databases/security/row-level-security
https://docs.microsoft.com/en-us/azure/synapse-analytics/security/synapse-workspace-access-control-overview
QUESTION 10
You are developing a solution that will stream to Azure Stream Analytics. The solution will have both streaming data and reference data. Which input type should you use for the reference data?
A. Azure Cosmos DB
B. Azure Blob storage
C. Azure IoT Hub
D. Azure Event Hubs
Correct Answer: B
Stream Analytics supports Azure Blob storage and Azure SQL Database as the storage layer for Reference Data.
Reference: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-use-reference-data
QUESTION 11
You have an activity in an Azure Data Factory pipeline. The activity calls for a stored procedure in a data warehouse in Azure Synapse Analytics and runs daily.
You need to verify the duration of the activity when it ran last.
What should you use?
A. activity runs in Azure Monitor
B. Activity log in Azure Synapse Analytics
C. the sys.dm_pdw_wait_stats data management view in Azure Synapse Analytics
D. an Azure Resource Manager template
Correct Answer: A
Reference: https://docs.microsoft.com/en-us/azure/data-factory/monitor-visually
QUESTION 12
You are designing an Azure Databricks cluster that runs user-defined local processes. You need to recommend a cluster configuration that meets the following requirements:
1.
Minimize query latency.
2.
Maximize the number of users that can run queries on the cluster at the same time.
3.
Reduce overall costs without compromising other requirements. Which cluster type should you recommend?
A. Standard with Auto Termination
B. High Concurrency with Autoscaling
C. High Concurrency with Auto Termination
D. Standard with Autoscaling
Correct Answer: B
A High Concurrency cluster is a managed cloud resource. The key benefits of High Concurrency clusters are that they provide fine-grained sharing for maximum resource utilization and minimum query latencies.
Databricks choose the appropriate number of workers required to run your job. This is referred to as autoscaling.
Autoscaling makes it easier to achieve high cluster utilization because you don\’t need to provision the cluster to match a workload.
Incorrect Answers:
C: The cluster configuration includes an auto terminate setting whose default value depends on cluster mode:
Standard and Single Node clusters terminate automatically after 120 minutes by default. High Concurrency clusters do not terminate automatically by default.
Reference: https://docs.microsoft.com/en-us/azure/databricks/clusters/configure
QUESTION 13
You have an Azure Synapse Analytics dedicated SQL pool.
You run PDW_SHOWSPACEUSED(dbo,FactInternetSales\’); and get the results shown in the following table.
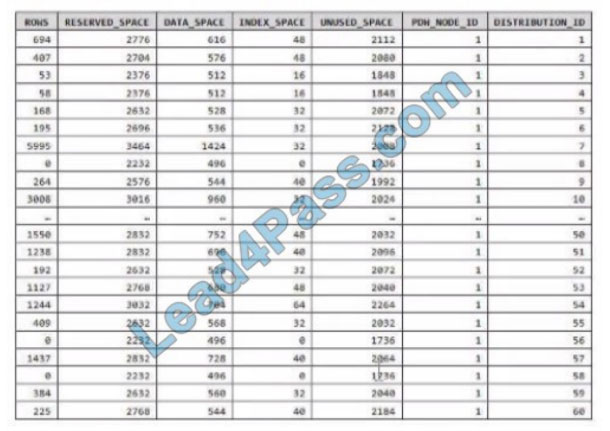
Which statement accurately describes the dbo, FactInternetSales table?
A. The table contains less than 1,000 rows.
B. All distributions contain data.
C. The table is skewed.
D. The table uses round-robin distribution.
Correct Answer: C
Data skew means the data is not distributed evenly across the distributions.
……
DP-203 Free Dumps Demo Online Download:https://drive.google.com/file/d/18TPwGvSzCs53MnjqYChKWm4298eGaUgV/
New DP-203 dumps https://www.leads4pass.com/dp-203.html for complete practice exam resources to help you successfully pass the Data Engineering on Microsoft Azure exam on your first attempt.